

La programmation d’applications web modernes, ce n’est pas compliqué. L’affichage final sur le client web est toujours réalisé en HTML + CSS + Javascript (même si l’on utilise un framework, ce sont toujours ces 3 items qui sont traités par le navigateur en bout de chaîne), et le traitement réalisé par le serveur repose sur une interface https en entrée/sortie, des traitements, et une interface bi- directionnelle avec une base de données.
L’interface https en entrée/sortie peut être réalisée par un serveur web dédié (NginX, Apache, …) ou être embarquée dans le ou les programmes de traitements.
Les programmes de traitements peuvent être écrits dans un très grand nombre de langages : Javascript, PHP, etc. Et notamment en langage C, qui est celui qui m’intéresse ici.
La base de données peut être SQL (MySQL, MariaDB, PostgreSQL, …) ou non.
Cette architecture est valable pour un très grand nombre de projets mis en œuvre sur internet, avec un très grand nombre de choix techniques faisables pour chaque brique.
Choix possibles pour le langage C
Le langage C est un langage très puissant, qui a eu son heure de gloire publique entre les années 70 et les années 2000. Tous les étudiants en informatique formés dans ces années (j’en fais partie) maîtrisent ce langage avec lequel on peut absolument tout faire, du système embarqué à l’application web.
Bien que ce langage soit moins en côte depuis une vingtaine d’années, du point de vue grand public en tout cas, il est en réalité omniprésent mais caché : le noyau Linux est écrit à 95% en C, l’interpréteur Python est écrit en C, git est écrit en C, Redis est écrit en C, NginX est écrit en C, FFMpeg est écrit en C, SQLite est écrit en C, etc. Les logiciels écrits en C sont les fondations silencieuses que nous utilisons quotidiennement sans même s’en rendre compte.
En ce qui me concerne, je suis particulièrement à l’aise avec le C et je développe mes applications web avec.
Pour développer des applications web en C il y a plusieurs choix possibles. Tout d’abord il existe des librairies C qui permettent de créer des applications C embarquant leur propre serveur web (libmicrohttpd, civetweb, nxweb, C web framework, lavandula, etc.).
Mais on peut aussi programmer en C derrière un serveur web classique, comme NginX ou Apache. C’est ce cas qui m’intéresse.
L’idée générale de cette architecture est que le serveur web NginX va gérer les échanges https avec les clients et envoyer une traduction des requêtes reçues à un programme, et ce programme peut être écrit dans n’importe quel langage, donc aussi en C.
Deux mécanismes existent historiquement pour réaliser cela : CGI et FastCGI
CGI (Common Gateway Interface)
C’est un mécanisme très simple et très ancien. Lorsque le serveur NginX reçoit une requête http destinée au script CGI (qui peut être écrit dans n’importe quel langage), il lance le script prévu dans un nouveau processus et lui transmet les données reçues traduites via 2 variables d’environnement (CONTENT_LENGTH qui contient la taille des data, et QUERY_STRING qui contient les data elles- mêmes). En fonction du mode http utilisé (GET, POST, DELETE, PATCH), il se peut que les data soient transmises sur l’entrée standard du script CGI et non dans la variable QUERY_STRING.
Le script CGI génère une page HTML sur sa sortie standard, et celle-ci est transmise au client via NginX qui sert de passe plat. A l’issue du traitement d’une requête client, le script CGI meurt (un autre script sera lancé et exécuté si une nouvelle requête arrive).
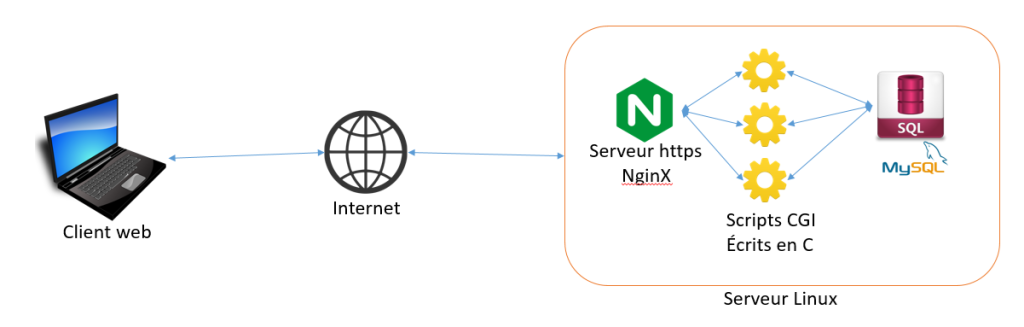
Dans la version moderne des scripts CGI le serveur web ne crée pas les scripts lui-même : il communique avec un programme intermédiaire (fcgiwrap) via la socket Unix /run/fcgiwrap.socket ou le socket réseau 127.0.0.1 :8999 selon comment il est paramétré. C’est ce programme intermédiaire fcgiwrap qui crée les processus nécessaires pour exécuter les scripts CGI au fur et à mesure des requêtes clients.
Les scripts CGI embarquent les routines nécessaires pour effectuer des requêtes SQL dans la base de données MySQL.
C’est ainsi que je programme mes backends depuis de nombreuses années.
Cette approche a deux problèmes principaux.
Le premier problème concerne la sécurité. En effet, il faut être très vigilant lorsqu’on programme ainsi car le script CGI peut être menacé de débordement de tampon (buffer overflow), d’injection SQL, voire de XSS (cross site scripting).
Ce premier problème ne m’a jamais gêné pour programmer avec les scripts CGI car j’ai l’habitude d’allouer dynamiquement (taille CONTENT_LENGTH) les variables destinées à récupérer les data en entrée, ainsi aucun buffer overflow n’est possible. De même, j’échappe systématiquement les caractères ‘ ce qui rend inopérant les injections SQL, et j’échappe également le caractère < ce qui rend inopérant le XSS (« <script> » non interprété par le navigateur).
Le deuxième problème est plus gênant car il concerne les performances, et notamment il ne permet pas de monter à l’échelle. En effet, à chaque requête client il y a création d’un processus Linux contenant le script CGI à exécuter. D’une part la création d’un processus est une opération longue pour le noyau Linux (bien plus longue que de lancer un thread par exemple). D’autre part, le nombre max de processus que le noyau Linux peut exécuter en parallèle est limité à quelques dizaines de milliers. Ce mécanisme de scripts CGI ne permet donc pas de créer un service web qui serait utilisé simultanément par des centaines de milliers de personnes. Il ne permet donc pas de monter un service massivement populaire.
C’est ce deuxième problème qui m’a poussé à trouver une alternative, si possible sans avoir à modifier le code C de mes scripts CGI. Cette alternative s’appelle FastCGI.
FastCGI
Vu de NginX il n’y a aucune différence entre CGI et FastCGI. Dans les deux cas NginX envoie dans une socket la traduction (variables CONTENT_LENGTH, QUERY_STRING, entrée standard) de la requête reçue, et renvoie vers le client les données qu’il récupère en réponse sur la socket.
La différence se situe de l’autre côté de la socket. Le programme qui y écoute n’est plus fcgiwrap mais spawn-fcgi. Plutôt de faire comme le ferait fcgiwrap (création d’un processus CGI à chaque requête), spawn-fcgi crée un processus CGI unique, persistant, qui traite toutes les requêtes les unes après les autres, et qui ne meurt jamais.
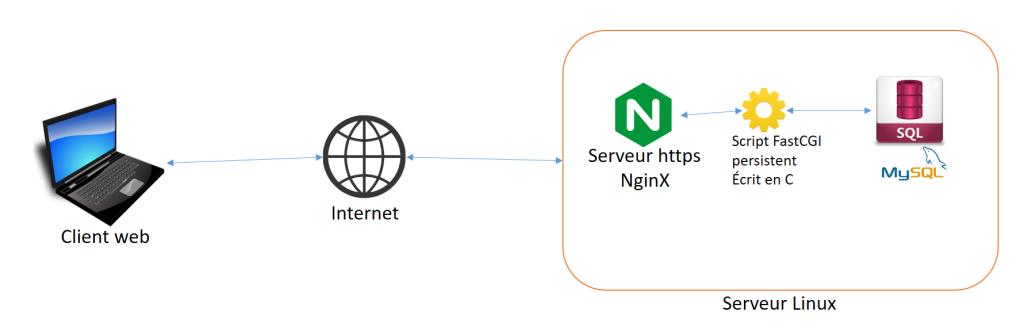
Rendre compatible avec fastcgi le code C d’un script CGI se fait facilement, en utilisant la librairie fcgi.
Concrètement, il faut remplacer dans le code source #include par :
#define _GNU_SOURCE
#include <fcgi_stdio.h>
Attention, cela a pour effet de ré-écrire la fonction printf traditionnelle pour qu’elle écrive non plus sur la sortie standard mais directement dans la socket fcgi. Autre conséquence de cette ré-écriture de printf : le flush via \n ne fonctionne plus, une fois les printf exécutés il faut faire fflush(stdout); pour qu’ils partent sur la socket.
Installation et utilisation de FastCGI
Maintenant que nous avons vu le concept, voyons la mise en œuvre concrète.
Tout d’abord il faut installer ce qu’il faut :
sudo apt update
sudo apt install spawn-fcgi libfcgi-dev
Le paquet spawn-fcgi contient l’outil nécessaire pour lancer des processus FastCGI en daemon.
Le paquet libfcgi-dev contient les bibliothèques et entêtes pour développer en C.
Ensuite il faut créer un paramétrage dans /etc/nginx/sites-enabled/default pour le service web qu’on veut créer (je vais l’appeler ici « api ») :
location /api/ {
fastcgi_pass unix:/var/run/mon-appli.socket;
include /etc/nginx/fastcgi_params;
fastcgi_param SCRIPT_FILENAME /home/toto/mon-appli;
fastcgi_param PATH_INFO $uri;
fastcgi_param QUERY_STRING $query_string;
fastcgi_param CONTENT_LENGTH $content_length;
fastcgi_param CONTENT_TYPE $content_type;
}
Pour que NginX prenne en compte le nouveau paramétrage :
sudo systemctl reload nginx
Ce paramétrage designe la socket Unix qui sera utilisée si un client envoie une requête à https://serveur/api (socket Unix /var/run/mon-appli.socket) et indique à NginX de transférer au script CGI les variables d’environnement PATH_INFO, QUERY_STRING, CONTENT_LENGTH et CONTENT_TYPE, dont on aura besoin dans le script CGI.
Le code source du script CGI mon-appli.c sera celui-ci :
#define _GNU_SOURCE
#include <fcgi_stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
while (FCGI_Accept() >= 0) {
printf("Content-Type : text/html\n\n");
printf("\n\nIci le script FastCGI\n\n");
fflush(stdout);
}
}
On compile ce programme par la commande :
gcc mon-appli.c -o mon-appli -lfcgi
Il reste à lancer spawn-fcgi de sorte qu’il lance et connecte de manière persistante ce script, avec la commande :
spawn-fcgi –s /var/run/mon-appli.socket –u www-data –g www-data -- /home/toto/mon-appli
Pour un lancement automatique au boot, il faut créer un service systemd (ou utiliser /etc/rc.local pour ceux qui savent recréer ce fichier qui a rendu bien des services à des générations d’unixiens).
Pour voir la réponse html envoyée par ce script, il suffit de taper depuis un client distant :
curl "https://serveur/api/test?nom=dupont"
Si vous jouez un peu avec les variables dans ce script en C, vous verrez que, suite à la commande ci- dessus getenv(« PATH_INFO ») ramène /api/test, getenv(« QUERY_STRING ») ramène « nom=dupont ».
Conclusion
Avec une telle architecture, on n’est pas embêté par la multiplication des processus inhérente à la montée en charge, et l’écriture des scripts CGI en C n’est pas modifiée (il suffit d’encadrer son code de la boucle while).